
Stop Memorizing Syntax. Start Modeling Intent.
When it comes to understanding SystemVerilog functions vs tasks, most engineers start with a quick checklist: functions return a value, tasks can consume time. That description is accurate, but it stops right where things begin to matter in real verification environments. Once you start building non-trivial test benches, the distinction is no longer about syntax, it is about how you model behavior in a time-driven simulation.
If that sounds abstract, it should. However, the moment you internalize it, your code starts looking different. Cleaner. More predictable. Easier to debug. Until then, it often works, but without life in it.
Let’s rebuild the idea from first principles.
Simulation is Not Software Execution
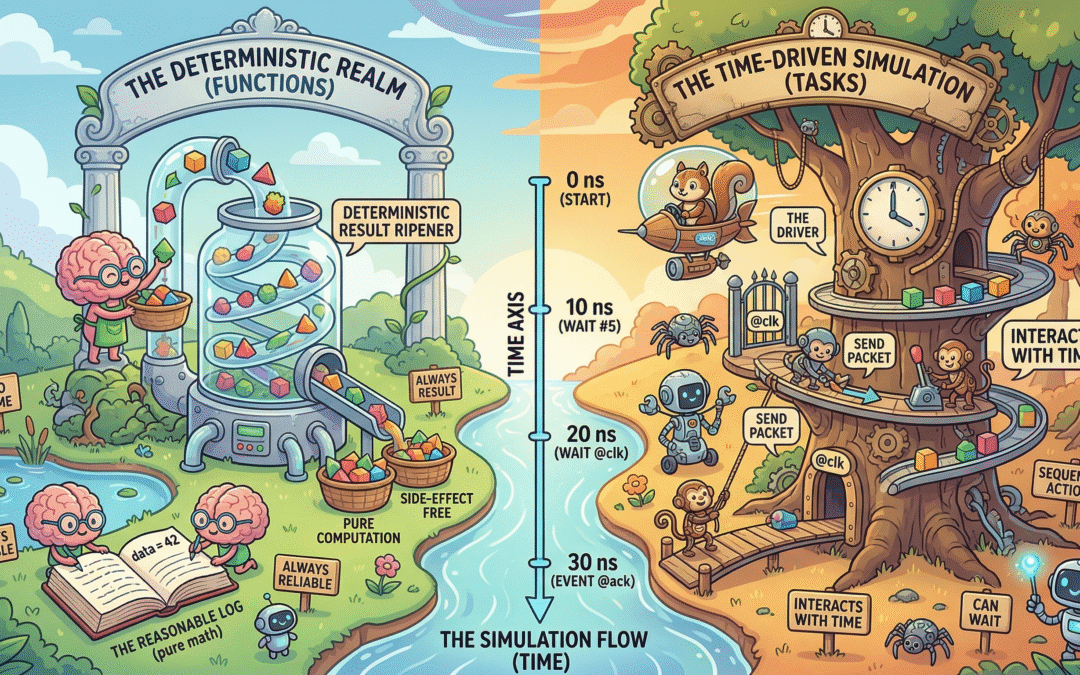
SystemVerilog does not execute like typical software. Instead, it models hardware behavior evolving over time. That single shift, from sequential execution to event based time-scheduled behavior, changes how every construct in the language should be used.
When you look at your code through that lens, everything naturally falls into two buckets. Some code computes a result immediately, independent of time. In contrast, other code interacts with time, waiting on clocks, reacting to events, coordinating concurrent activity. The distinction is fundamental, not stylistic.
As a result, functions belong to the first category. Tasks belong to the second.
SystemVerilog Functions: Pure Computation, No Time
A function represents pure computation. Conceptually, it behaves like combinational logic: inputs go in, an output comes out, and nothing in between depends on time. There is no waiting, no scheduling, and no hidden ordering effects.
This is why functions execute in zero simulation time and cannot contain delays or event controls. More importantly, this is why they are reliable. A function answers a question: given the same inputs, it will always produce the same output, regardless of when or where it is called.
That property, determinism, is what makes functions invaluable in verification. Scoreboards rely on them to compute expected values. Reference models use them to mirror DUT behavior. Constraint helpers depend on them to remain side-effect free. If you want to see how the UVM Factory pattern leverages these constructs, that post dives deeper into the topic.
Consider a simple example from a scoreboard:
function int predict_crc(bit [31:0] data);
int crc;
// Pure computation, no timing
crc = data ^ (data >> 16);
return crc;
endfunctionThere is nothing surprising here. No @, no #, no implicit ordering. Just logic. And that simplicity is precisely the point.
SystemVerilog Tasks: Modeling Behavior Over Time
Tasks, in contrast, exist to model behavior that unfolds over time. They are where your testbench interacts with the DUT, with clocks, and with the rest of the simulation world. If a piece of code needs to wait, synchronize, or sequence activity, it belongs in a task.
A task does not answer a question rather it performs an action. It sends a packet. It waits for a response. It drives a protocol. It sequences transactions across cycles. These are inherently time-aware operations, and trying to force them into a time-independent abstraction is where things begin to break.
A typical driver routine makes this explicit:
task drive_packet(packet pkt);
@(posedge clk);
valid <= 1;
data <= pkt.data;
@(posedge clk);
valid <= 0;
endtaskEvery line communicates intent. Time advances. Signals change. As a result, the behavior is visible and predictable because the timing is explicit.
Where Things Go Wrong with Functions vs Tasks
Most verification issues around SystemVerilog functions vs tasks do not come from misunderstanding syntax. Instead, they come from blurring the boundary between computation and time.
When time is hidden, especially inside something that appears to be pure computation, the entire mental model collapses. Engineers start reasoning about code as if it were deterministic, while the simulator is quietly scheduling events underneath.
That mismatch leads to some of the most frustrating bugs in verification: non-determinism, ordering issues, and failures that disappear when you add debug prints. Understanding SystemVerilog macros and their pitfalls can also help you avoid similar hidden complexity.
A simple anti-pattern captures this mistake:
function int get_data();
@(posedge clk); // Conceptual violation
return bus_data;
endfunctionEven if the language forbids this directly, similar patterns creep in through indirect abstractions. The problem is not just legality, it is intent. A function that depends on time is no longer a function in the conceptual sense, and treating it as one creates misleading code.
The Golden Rule
The discipline that keeps large environments sane is surprisingly simple: never hide time. If time advances, it should be obvious from the structure of your code. Functions remain strictly time-independent. Tasks make time explicit. This separation is not a style preference, it is what allows engineers to reason about behavior without constantly second-guessing the simulator.
Arguments: How Data Flows Through Functions and Tasks
So far we have treated functions as computation and tasks as time-based behavior or action. The next layer of understanding is how data flows through them. This is where argument types and passing semantics start to matter, not as syntax, but as contracts about ownership, visibility, and side effects.
Inputs: Read-Only Intent
An input argument represents data that is consumed, not modified. Conceptually, you are saying: “I need this value to compute something, but I will not change it.” This aligns naturally with functions, which are expected to be side-effect free.
function int compute_sum(int a, int b);
return a + b;
endfunctionEven in tasks, using inputs clearly communicates that the data is only being observed. The important idea is not direction, but intent. Inputs protect reasoning. When you read a function with only inputs, you know it cannot secretly modify external state.
Outputs: Explicit Side Effects
An output argument flips the contract. Now the routine is responsible for producing a value and writing it back to the caller.
task read_data(output int data);
@(posedge clk);
data = bus_data;
endtaskOutputs are common in tasks because tasks already represent actions. Writing results back is part of that behavior. However, there is a subtle cost: outputs introduce state mutation, which means the caller must now track what changed. Overuse of outputs can make code harder to reason about, especially in large environments.
Default Arguments: Reducing Friction
Default arguments let you design routines that are simple to use in the common case, while still flexible when needed.
function int increment(int value, int step = 1);
return value + step;
endfunctionConceptually, this is about API ergonomics, not just convenience. The danger is subtle if defaults hide important behavior, they reduce clarity. Used well, they reduce boilerplate without hiding intent.
ref: Sharing State Intentionally
A ref argument does not copy data. It provides a direct reference to the original variable. Any modification inside the routine affects the caller immediately.
task update_counter(ref int count);
count++;
endtaskThis is powerful and dangerous at the same time. Using ref means you are mutating shared state. In a time-scheduled simulation, sharing state across processes can introduce race conditions if not handled carefully. Use ref when you truly need in-place updates, not as a shortcut to avoid returns or outputs.
const ref: Performance Without Losing Safety
const ref combines two ideas: it avoids copying data like ref, but enforces read-only access like input.
function int checksum(const ref bit [1023:0] payload);
// Large data, no copy, no modification
endfunctionThis becomes critical when dealing with large transactions or complex objects. Passing by const ref avoids copy overhead while preserving the guarantee that the function will not modify the data. Conceptually, const ref is about efficiency without sacrificing determinism.
The Deeper Pattern
At a higher level, argument types reinforce the same philosophy we saw earlier. Functions prefer input and const ref because they preserve purity. Tasks can use output and ref because they already model side effects. The goal is to make data flow and side effects obvious from the interface itself.

How Functions vs Tasks Show Up in UVM
Once you move into UVM, the separation between SystemVerilog functions vs tasks becomes even more critical. The entire methodology is built around clear roles for data, behavior, and communication.
A scoreboard is fundamentally evaluative, it should not influence time, only analyze data. Its core logic is naturally function-based:
function bit compare(packet exp, packet act);
return (exp.data == act.data);
endfunctionA driver, on the other hand, is inherently time-driven. It interacts with the DUT across cycles and must therefore be implemented using tasks:
task run_phase(uvm_phase phase);
forever begin
seq_item_port.get_next_item(req);
drive_packet(req);
seq_item_port.item_done();
end
endtaskMonitors naturally straddle both worlds: they observe signals over time using tasks, then process and package that data using function-like logic. Similarly, sequences orchestrate time-based stimulus while relying on functions for data manipulation. The pattern repeats because the underlying principle is consistent.
The Subtle Trade-off
With experience, you start encountering cases where either a function or a task could work. This is where judgment matters more than rules.
Choosing a task when no time interaction is required introduces unnecessary constraints, the code becomes harder to reuse, harder to compose, and subtly tied to simulation ordering. A simple question usually resolves the ambiguity: does this behavior require time to progress? If it does, it belongs in a task. If it does not, it should remain a function.
A Real Debug Story
Consider a case that shows up more often than it should. A utility routine is initially written as a task “just in case” it might need flexibility later. During debugging, someone adds a #0 delay inside it to observe ordering effects. The change seems harmless.
Nothing breaks immediately. But over time, subtle issues start appearing: race conditions between parallel processes, intermittent mismatches in the scoreboard, failures that cannot be reproduced consistently.
The root cause is not the delay itself. It is the fact that time was introduced into a place where everyone assumed there was none. Had the routine been modeled as a function, the bug would not have been possible. For more on debugging strategies in UVM configuration, check out that guide.
Why SystemVerilog Functions vs Tasks Matter Even More Today
Verilog already distinguished between tasks and functions, but SystemVerilog made that distinction central to verification architecture. With class-based testbenches, automatic lifetimes, constrained random stimulus, and coverage-driven flows, these constructs are no longer just syntactic tools — they define how intent is expressed in a scalable environment.
Think Like the Simulator
The most useful mental shift is to stop thinking in terms of code execution and start thinking in terms of scheduling. You are not writing instructions for a CPU, you are describing behavior for a simulator that coordinates events over time.
Seen that way, the distinction becomes natural. Some parts of your code compute results. Others describe how those results come into existence over time. Mixing the two is what creates confusion.
Final Takeaway
SystemVerilog functions vs tasks are not just language features. They are a contract with the simulator. A function promises that it will not consume time. A task admits that it might. That contract is what allows engineers to reason about complex systems without constantly questioning execution order.
Break that contract, and the environment becomes unpredictable. Respect it, and the system becomes deterministic, debuggable, and scalable, the qualities that matter most when verification complexity grows.